H. Sanneck
GMD Fokus
Kaiserin-Augusta-Allee 31
D-10589 Berlin, Germany
sanneck@fokus.gmd.de
Today's Internet is increasingly used not only for e-mail, ftp and WWW,
but for interactive audio and video services (MBone [1]). However, the
Internet as a datagram network offers only a ``best effort'' service,
which can lead to excessive packet losses under congestion. Internet
measurements have shown that the overall probability to loose one
packet is high, however drops significantly for the loss of several
consecutive packets ([2], [3]).
In this paper we consider this Internet loss characteristic and the property of long-term correlation within a speech signal together, to mitigate the impact of packet losses. This is accomplished by an adaptive choice of the packetization interval of the voice stream at the sender. When a packet is lost, the receiver can use adjacent signal segments to conceal the loss to the user, because a high similarity can be assumed due to the adaptive packetization at the sender. The subjective quality of the proposed scheme as well as its applicability within the current Internet environment (high loss rates, common audio tools, standard speech codecs) are discussed.
To tackle the problem of lost packets (which for speech transmission means annoying signal drop-outs and a possibly disrupted conversation), different techniques have been proposed, which can be divided as follows:
Further compression of the speech signal leads to a reduction in the overall amount of data to be sent over the network, i.e. the payload per packet is reduced. Yet the number of packets stays the same (when maintaining the packetization time interval), thus inducing the same per-packet processing cost as before in the network.
Due to the nature of current speech codecs, also
adaptation of the coder output bitrate to the network conditions, as well as a layered distribution of the coder output signal is
not feasible. We therefore propose a scheme called Adaptive Packetization and
Concealment (AP/C, [15]) and discuss its applicability in the Internet/Mbone environment.
The paper is structured as follows:...
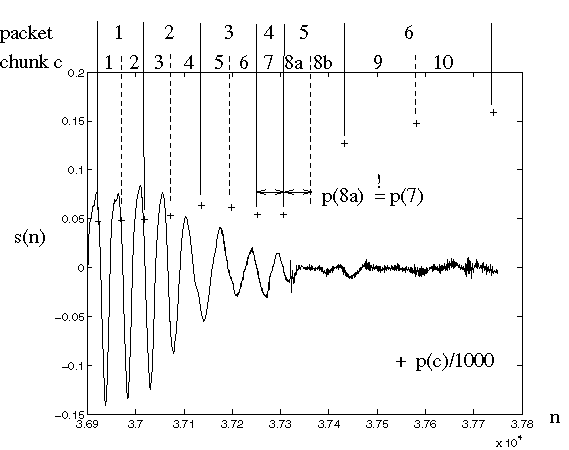
If no periodicity was found in the signal (i.e. the content of the "chunk" is unvoiced speech or noise), p(c) is close to pmax (Fig. 1). Thus, by applying a fixed bound pu (minimal length of a chunk classified as ``unvoiced'') to p(c) and p(c-1), as well as applying another bound ![]() to the first derivative of p(c), it is possible to detect speech transitions. The detection routine may run in parallel and can be combined with silence detection.
to the first derivative of p(c), it is possible to detect speech transitions. The detection routine may run in parallel and can be combined with silence detection.
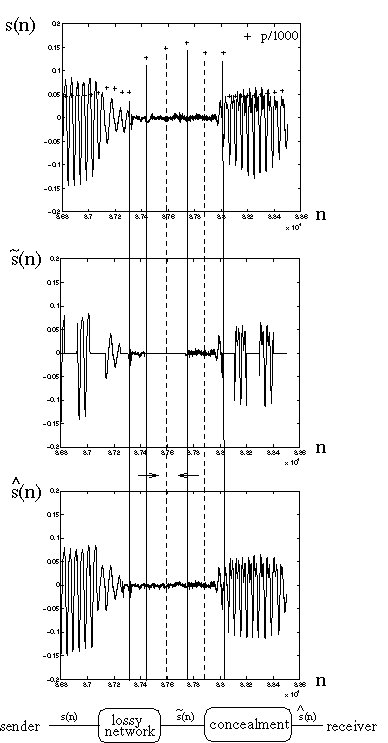
To alleviate the incurred header overhead, which would be prohibitive for IP if every chunk is sent in one packet, two consecutive chunks are associated to one packet (see figures 1 and 2, s(n): time domain signal n: sample number).
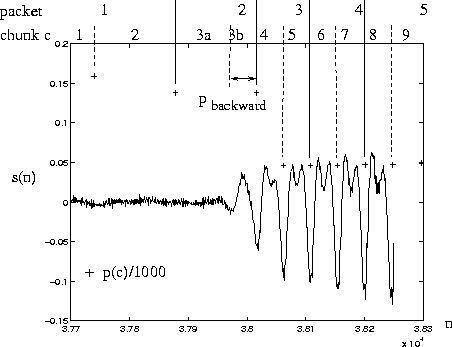
When a uv transition has taken place, backward correlation of the current chunk with the previous one (no. 3 in Fig. 2) is tested as it may already contain voiced data (due to the forward auto-correlation calculation). If true, again the previous chunk is partitioned with p(cb-1)=pbackward(c-1) and p(ca-1)=p(c-1)-p(cb-1) (pbackward is the result of the backward correlation). Note that the above procedure can only be performed if cmod2 = 0, otherwise the previous chunk has already been sent in a packet. A solution to this problem would be to retain always two unvoiced chunks and check if the third contains a transition, however the gain in speech quality when concealing would not justify the incurred additional delay.
 |
With our scheme, the packet size is now adaptive to the measured pitch period.
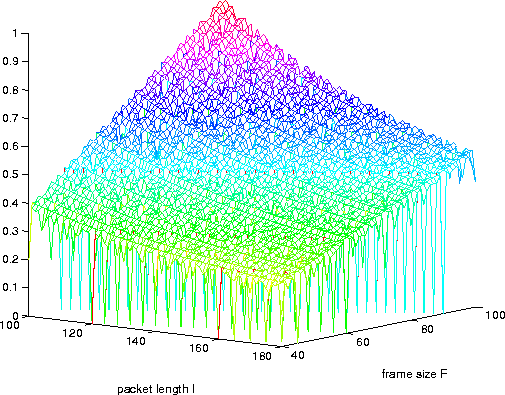
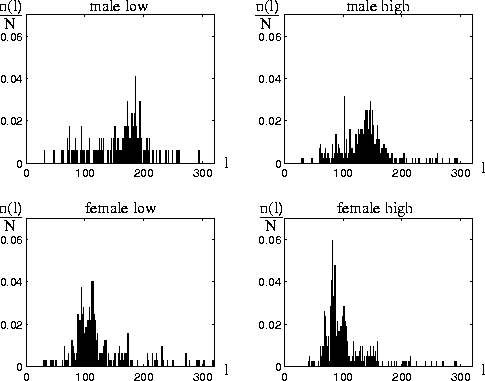
Distributions of the packet size for four different speakers in Fig. 3 show that the parameter settings can accomodate a range of pitches, as their overall shapes are similar to each other (parameters were:
pmin=30 samples (start offset point of the auto-correlation); pu=120; pmax=160; note that pmin <= l <= 2 pmax). The most common packets contain two voiced chunks (vv packets), as distributions are centered around a value that is twice the mean pitch period (i.e. the mean of voiced chunks).
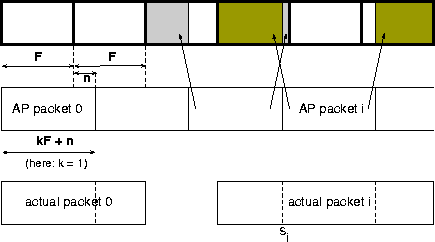
Fig. 4 shows the packetization, when speech boundaries found by the AP algorithm are used to associate frames of length F to the actual packets sent over the network. As AP packets overlap the frame boundaries, a significant amount of redundant data, as well as additional alignment information (si) needs to be transmitted (yet redundant data can be used in a possible concealment operation e.g. by overlap-adding it to the replacement signal). To allow analysis, we assume a constant AP packet size of l=kF+n, k being a positive integer.
The fragmentation data ``overhead'' associated with packet i can then be written as follows:
![]()
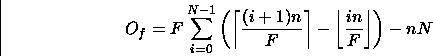
When detecting a lost packet (by keeping track of RTP [19] sequence numbers), the receiver can assume that the chunks of a lost packet resemble the adjacent chunks, because of the pre-processing at the sender. To avoid discontinuities in the concealed signal, the adjacent chunks are copied and resampled (using an up/down sampler with linear interpolator) to exactly fit the lost chunk sizes, which are given by the packet length and the transmitted intra packet boundaries. No time-scale adjustment ([14]) is necessary as the chunk sizes are very small. As the sizes of the lost and the adjacent chunk most probably only differ slightly (and thus the respective spectra), no significant audible impact of the operation can be observed.
Fig. 6 shows the concealment operation in the time domain.
Transitions in the signal might lead to extreme expansion/compression operations, because the length of an unvoiced chunk of a transition packet (denoted v|u or u|v) will be usually significantly smaller than in u|u packets (two unvoiced chunks). This is due to the chunk partitioning described in section "Adaptive packetization of speech transitions".
Table 1 lists the possible cases (va, ua are (the relevant) voiced/unvoiced available chunks, vL, uL are (the relevant) voiced/unvoiced lost chunks. A u (u|v) packet is a packet where the second chunk contains an unvoiced/voiced transition that was not recognized by the sender algorithm. To avoid high compression, adjacent samples of the relevant length are taken and inserted in the gap. An audible discontinuity which might occur can be avoided by overlap-adding the concealment chunk with the adjacent ones. High expansions can be avoided by repeating a chunk until the necessary length is achieved and then again overlap-adding it.
To evaluate the properties and performance of AP/C a subjective test was carried out. Test signals were the four signals (with different speakers) of approximately 10 seconds each, also used for the objective analysis (PCM 16 bit linear, sampled at 8 kHz). The new technique was compared against silence substitution (i.e. an adaptive packetization without concealment) and the simple receiver-based concealment algorithm ``Pitch Waveform Replication'' (PWR), which is the only one able to operate under very high loss rates (isolated losses). For PWR we used the same algorithm and fixed packet size (160 samples) as in [14].
Seven non-expert listeners ![]() evaluated the overall quality of 40 test conditions (4 speakers x [3 algorithms x 3 loss rates + original]) on a five-category scale (Mean Opinion Score). Tests took place in a quiet room with the subjects using headphones.
evaluated the overall quality of 40 test conditions (4 speakers x [3 algorithms x 3 loss rates + original]) on a five-category scale (Mean Opinion Score). Tests took place in a quiet room with the subjects using headphones.
The same packet loss pattern was applied to all input signals for one speaker (note that the sample loss pattern is different due to PWR working on fixed packet sizes only). To allow complete concealment and thus a relative evaluation of the algorithms, only isolated losses were introduced. Therefore we used a probability density function which satisfies the condition Pi(i|i-1) = 0 (Pi(i|i-1) is the conditional probability of packet i being lost when packet i-1 has been lost) and approximates at the same time an equally distributed loss behaviour with a given sample loss rate ([15]).
Before testing started, an ``Anchoring'' procedure took place, where the quality range (Original = 5, ``Worst Case'' signal = 1) was introduced. For this test we used the unconcealed 50% loss signal (with AP) as the ``Worst Case'' signal.
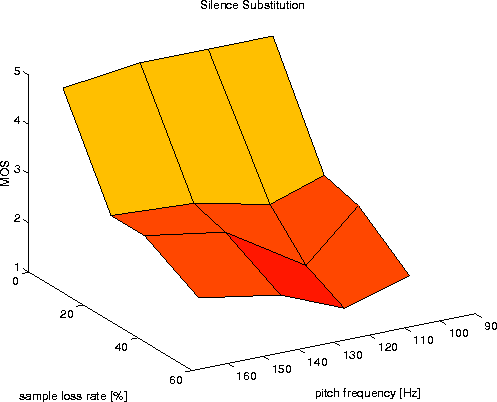
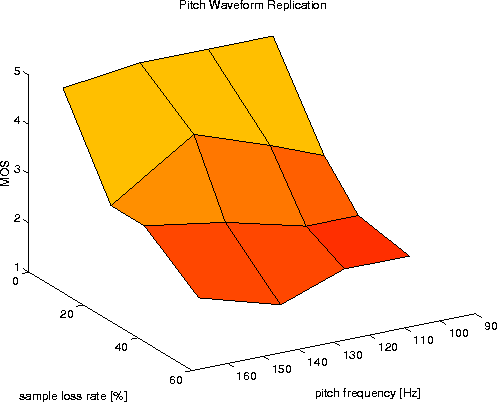
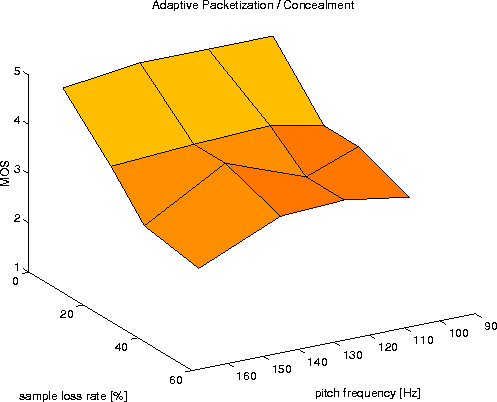
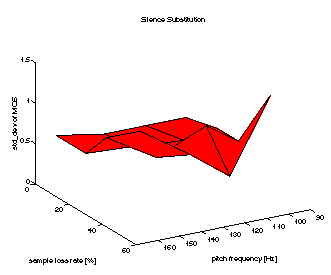
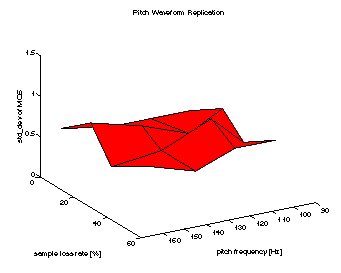
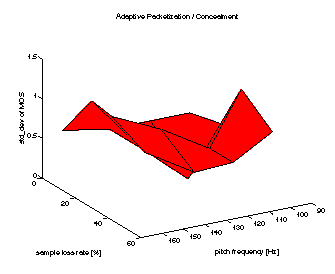
Figures 7-9 show the mean MOS values for the three algorithms (Silence Substitution, Pitch Waveform Replication and AP/C). Figure 10 gives the respective standard deviations of the MOS. As loss values we give the actual sample loss rate instead of the packet loss rate, as we deal with variable size packets. The pitch frequency axis refers to the measured mean of voiced chunks.
It can be seen that for all speakers AP/C leads to a significant enhancement in speech quality compared to the ``silence substitution'' case, which tends to relatively increase with higher loss rate. However for speakers with a very high pitch frequency, the relative performance decreases. A reason for this is the chosen start offset point pmin (= 30 samples) of the auto correlation computation, which constitutes a lower bound on the chunk/packet size to avoid excessive packet header overhead, but also limits the accurateness of the periodicity measurement (note the small distance between the peak of the packet size distribution and the lower bound in Fig. 3 for ``female high''). Additionally ``female high'' has the highest MOS for the worst case signal (2.0). This is due to the adaptive packetization (a high number of small-length ``gaps'' are introduced into the signal which are less intelligible).
The PWR algorithm performs well for loss rates of about 20% (cf. [14]), however speech quality drops significantly for higher loss rates, as the specific distortions introduced by that algorithm become increasingly audible.
Subjective tests have been performed with PCM samples, this carries the implicit assumption that the speech immediately after the gap is decoded properly. However modern speech coders rely on synchronization of coder and decoder, which is lost during a packet loss gap ([20]) thus the decoding is of course worse after the gap due to previous coder state loss.
Objective measurements are clearly inappropriate for PWR (no aim at mathematical approximation of the missing signal segments). AP/C is not a reconstruction scheme as well, however the adaptive packetization and subsequent resampling should perform better concerning mathematical correctness. Calculated overall SNR values for PWR (for the examples which are presented in this paper) are always below those for the distorted signal. SNR values for AP/C are always above those for the distorted signal and at least 4dB higher than for PWR. This confirms our conjecture, yet conclusions about speech quality should be only based on the subjective test results.
The maximum additional delay introduced in the current implementation consists of
To support a possible concealment operation it is necessary to transmit the intra-packet boundary between two chunks as additional information in the packet itself and the following packet. That amounts to two octets of ``redundancy'' for every packet, that could e.g. be transmitted by the proposed redundant encoding scheme ([21]).
When the frame length F is significantly smaller than the mean packet size (section "Support for frame-based codecs", Fig. 5), support for frame-based codecs can be assured with a reasonable amount of additional data.
A technique for the concealment of lost speech packets has been presented. The core idea of preprocessing a speech signal at the sender to support possible concealment operations at the receiver has proven to be successful. It results in an inherent adaptation of the network to the speech signal, as predefined portions of the signal (``chunks'' assembled to packets) are dropped under congestion.
Backwards compatibility to existing audio tools is ensured, as most tools can receive properly variable length PCM packets (and then mix them into their output buffer), however delay adaptation algorithms might need to be modified.
The subjective quality, when using AP/C in conjunction with existing frame-based codecs needs to be evaluated in further subjective tests. However, a more efficient scheme integrating the coder and appropriate packetization should be devised. We also plan to test more sophisticated speech classification / processing algorithms, yet always taking into account the compromise of quality and computational complexity.
From the perspective of the network, the presented application level scheme could be complemented by influencing loss patterns at congested routers (queue management), thus also supporting more fairness between flows by avoiding bursty losses within one flow.